
シリーズ: Claudeで変わる仕事術 上級・第3弾 / 前回:上級・第2弾 毎回ゼロから説明しない。Claudeに「覚えて育つ記憶」を持たせる
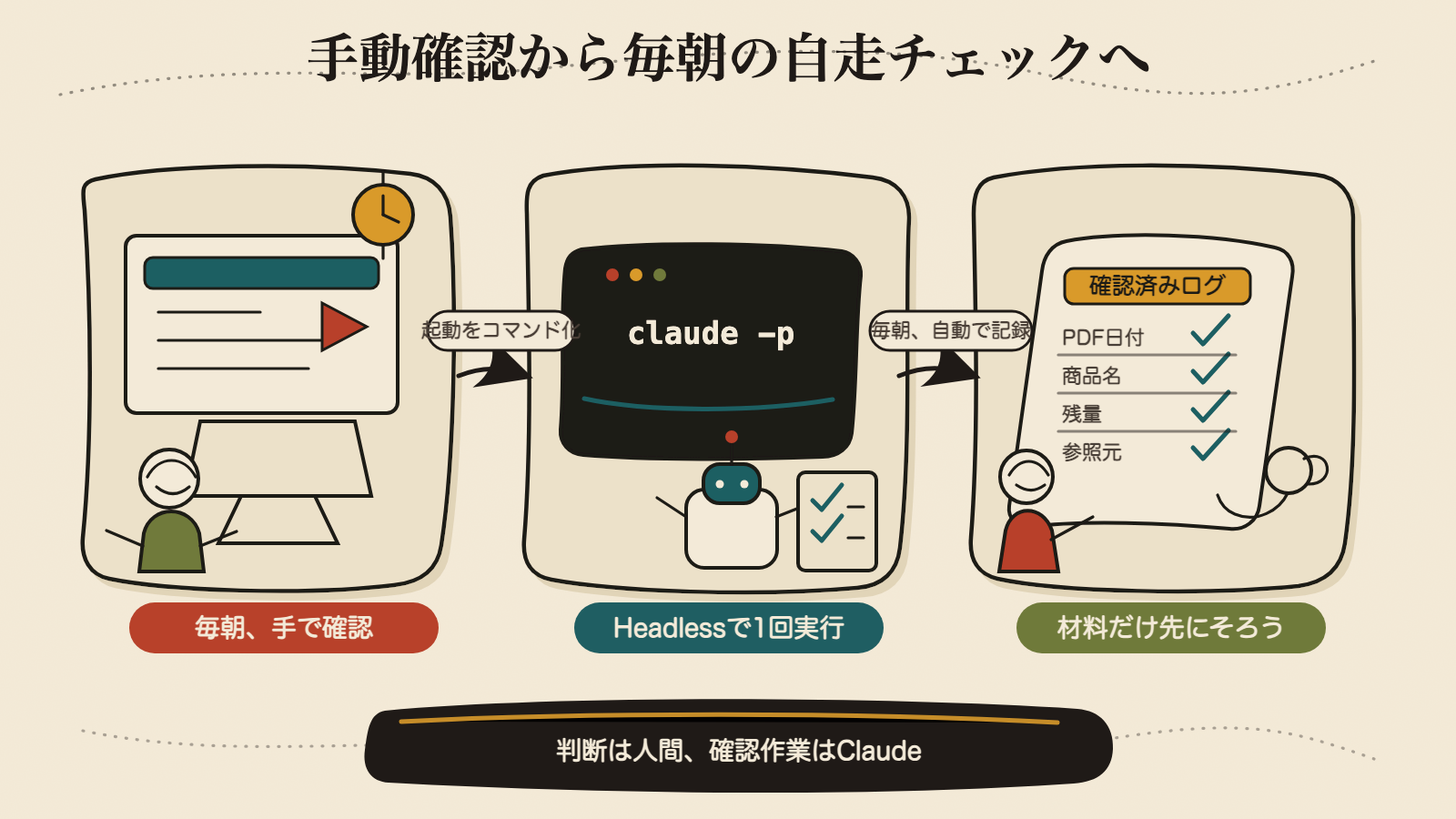
毎朝、同じサイトを開く。
最新のPDFが出ていないか見る。
出ていたらPDFを開く。
自分が見たい商品名を検索する。
残量をメモする。
こういう仕事は、地味に多い。
派手なAI活用ではない。 でも、現場ではこういう確認作業が時間を食う。
前回までに、Claude Codeの仕組みはかなり育ってきた。
第1弾では、SkillやHookをPluginという箱にまとめた。 第2弾では、ClaudeにMemoryを持たせて、こちらの好みや注意点を覚えさせた。
でも、まだ最後のひと手間が残っている。
自分で起動している。
今回は、そこを手放す。
Claude Codeを対話画面で開かず、コマンド一発で動かす。 さらに、決まった時間に自動で動く形にする。
テーマは、起動すら要らない仕組みだ。
1. 「一行で起動」の次に来る悩み
中級編では、Skillを作った。
たとえば、経費精算フローを一行で起動できるようにした。
/expense-check
これは大きな前進だった。
毎回、長い手順を説明しなくていい。 決まった仕事を、決まった型で動かせる。
でも、慣れてくると次の不満が出る。
「その一行を打つのも、毎回だと面倒だな」
たとえば、こういう仕事だ。
- 毎朝、取引先サイトの新着PDFを確認する
- 毎週、未処理チケットをまとめる
- 毎月、請求書フォルダを見て不足を確認する
- 毎日、競合ニュースを拾って要点だけ読む
人間が判断しているように見えて、実際には「探す、読む、抜き出す」だけの時間が多い。
この部分は、自走させやすい。
もちろん、全部を任せるわけではない。
発注する。 申請する。 送信する。 承認する。
こういう判断や実行は、人間が持つ。
Claudeに任せるのは、その手前だ。
毎朝の確認材料を、先にそろえてもらう。
これだけでも、朝の仕事はかなり軽くなる。
2. Headlessとは何か
Claude Codeは、ふつう対話式で使う。
ターミナルで claude と打つ。
画面が開く。
そこに依頼を書く。
Claudeが返す。
これがいつもの使い方だ。
一方で、Claude Codeには Headless という使い方がある。
対話画面を開かず、コマンドだけで1回実行して終わるモードだ。
基本形はこれ。
claude -p "今日の確認作業を実行して"
-p は --print の短い書き方。
Claudeに1回だけ依頼して、結果を標準出力に返す。
画面を開いて会話するのではなく、シェルの中で動く。 だから、スクリプトや定期実行に組み込める。
出力はファイルに残せる
claude -p の結果は、標準出力に出る。
ファイルに残したいときは、ふつうのシェルと同じように > を使う。
claude -p "今日の確認作業を実行して" > result.txt
追記したいときは >> を使う。
claude -p "今日の確認作業を実行して" >> daily-log.txt
毎朝の確認作業では、この >> がよく使える。
昨日のログを消さず、今日の結果を下に足せるからだ。
JSONで受け取って、本文だけを保存したいなら jq を使う。
claude -p "今日の確認作業を実行して" --output-format json \
| jq -r '.result' > result.md
claude -p に「このファイルへ保存」という専用オプションがあるわけではない。
保存先は、シェルの > / >> で決める。
--output-formatで選べる形式
--output-format は、Claudeの返し方を決めるオプションだ。
現在使える値は3つ。
| 値 | 使いどころ |
|---|---|
text | ふつうの文章で返す。指定しなければこれ |
json | 結果、コスト、session_idなどをJSONで返す |
stream-json | 長い処理をリアルタイムに流しながら受け取る |
基本は text でいい。
後続のスクリプトにつなぐなら json が向いている。
claude -p "OKだけ返して" --output-format json
返り値は、だいたいこういう形になる。
{
"type": "result",
"subtype": "success",
"result": "OK",
"session_id": "...",
"total_cost_usd": 0.02
}
実際に使いたい本文は、result に入る。
CSVで返したい場合、--output-format csv はない。
CSVがほしいときは、Claudeへの依頼文でCSV形式を指定して、ファイルへ保存する。
claude -p "次の内容をCSVで返して。列はdate,item,value。" > output.csv
Toolsは必ず絞る
自走させるときに大事なのは、Claudeに許可する操作範囲だ。
何でもできる状態で毎朝動かすのは危ない。
Toolsは、主に3つの指定方法がある。
| オプション | 役割 |
|---|---|
--tools | 使えるツール全体を指定する |
--allowedTools | 許可するツールを指定する |
--disallowedTools | 禁止するツールを指定する |
たとえば、読むだけにする。
claude -p "このフォルダのメモを読んで要約して" \
--tools "Read" \
--output-format json
Bashを使わせる場合は、さらに細かく絞る。
claude -p "curlでページを取得して、最新PDFリンクを探して" \
--allowedTools "Bash(curl *),Bash(rg *),Bash(sed *)" \
--output-format json
Bash を丸ごと許可しない。
Bash(curl *) のように、使っていいコマンドを狭く書く。
代表的なTool名はこのあたりだ。
| Tool | できること |
|---|---|
Read | ファイルを読む |
Write | ファイルを書く |
Edit | ファイルを編集する |
MultiEdit | 複数箇所をまとめて編集する |
Bash | シェルコマンドを実行する |
Glob | ファイルパターンで探す |
Grep | ファイル内を検索する |
LS | ディレクトリを見る |
WebFetch | Webページを取得する |
WebSearch | Web検索する |
TodoWrite | Claude内部の作業リストを更新する |
ただし、使えるToolは環境や設定で変わる。
MCPを入れていれば、mcp__... 形式のツールも増える。
PluginやSkillの影響で動き方が変わることもある。
だから、定期実行では --safe-mode を付けると安定しやすい。
claude --safe-mode -p "python3 /Users/you/cbp-check/cbp_check.py SUGAR を実行して結果を要約して" \
--add-dir /Users/you/cbp-check \
--allowedTools "Bash(python3 /Users/you/cbp-check/cbp_check.py *)" \
--output-format json
この例では、Claudeが実行できるのは cbp_check.py だけだ。
今回よく使うオプションだけ、先にまとめておく。
| オプション | 役割 |
|---|---|
-p / --print | 非対話で1回実行する |
--output-format json | 結果をJSONで返す |
--allowedTools | Claudeが使えるツールを絞る |
--max-turns | 最大ターン数を決める |
--cwd | 作業フォルダを指定する |
--safe-mode | ローカルのSkillやHookの影響を切って動かす |
読むだけなら Read。
Webページを見るだけなら WebFetch。
ただし、サイトによっては WebFetch をブロックする。
今回使うCBPのページも、そのまま WebFetch で読むと403になることがある。
その場合は、curl でページやPDFを取得し、Claudeには結果の読み取りを任せる。
自走の最初は、強い権限を使わない。
読む、探す、ログに残す。 そこから始める。
自走の第一歩は、便利にすることではない。
任せる範囲を狭く決めることだ。
3. 自走させる前に、安全線を決める
今回の実践では、米国税関・国境警備局(CBP)のページを例にする。
Commodity Status Report というページだ。
このページには、Commodity Graph Reportが掲載される。 CBPの説明では、通常は毎週最初の営業日に更新され、現在のレポートと過去4回分が参照できる。
2026年6月26日に確認した時点では、ページ上の最新添付は Quota Status Report: June 22, 2026 だった。
このページを毎朝見に行き、最新PDFを確認し、指定商品の残量を抜き出す。
業務でありそうな流れだ。
ただし、ここで線を引く。
Claudeに任せること。
- ページを見る
- 最新PDFを見つける
- 必要ならPDFをダウンロードする
- 指定商品を探す
- 残量、対象期間、参照元をまとめる
Claudeに任せないこと。
- 発注判断
- 在庫判断
- 申請
- メール送信
- 社内システムへの登録
- 数字の最終確定
ここを混ぜると危ない。
自走とは、AIに全部任せることではない。
人間が毎日やっている確認作業を、決まった範囲で先に済ませてもらうことだ。
4. 🛠️ 最新PDFを毎日チェックして、指定商品の残量を確認する
ここから手を動かす。
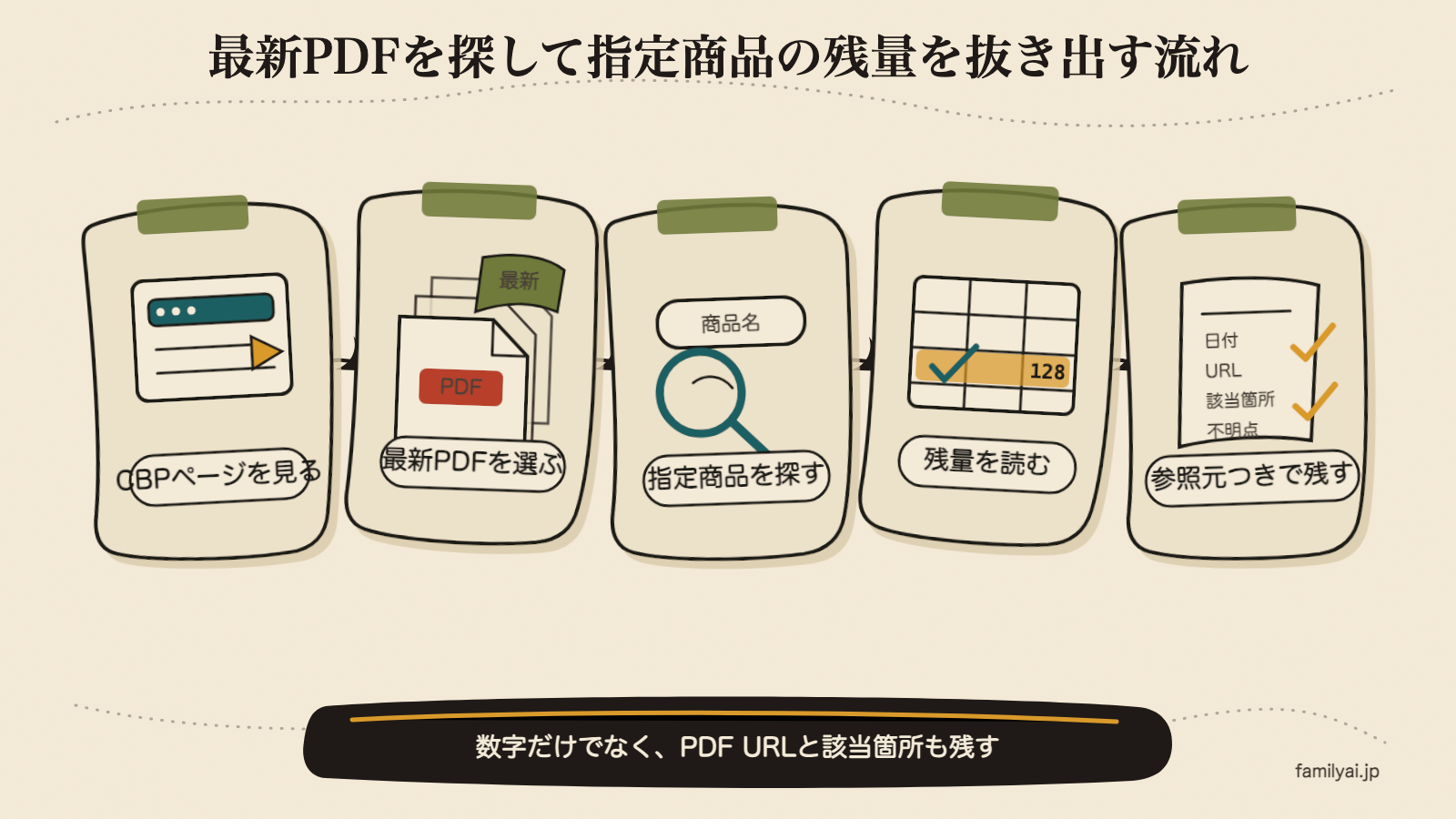
今回のゴールはこうだ。
CBPのページを見る
↓
最新PDFを見つける
↓
PDFを確認する
↓
指定商品の残量を抜き出す
↓
結果をログに残す
ステップ1:まずは最新PDFだけ探す
いきなり残量まで読ませない。
最初は、最新PDFを見つけるだけにする。
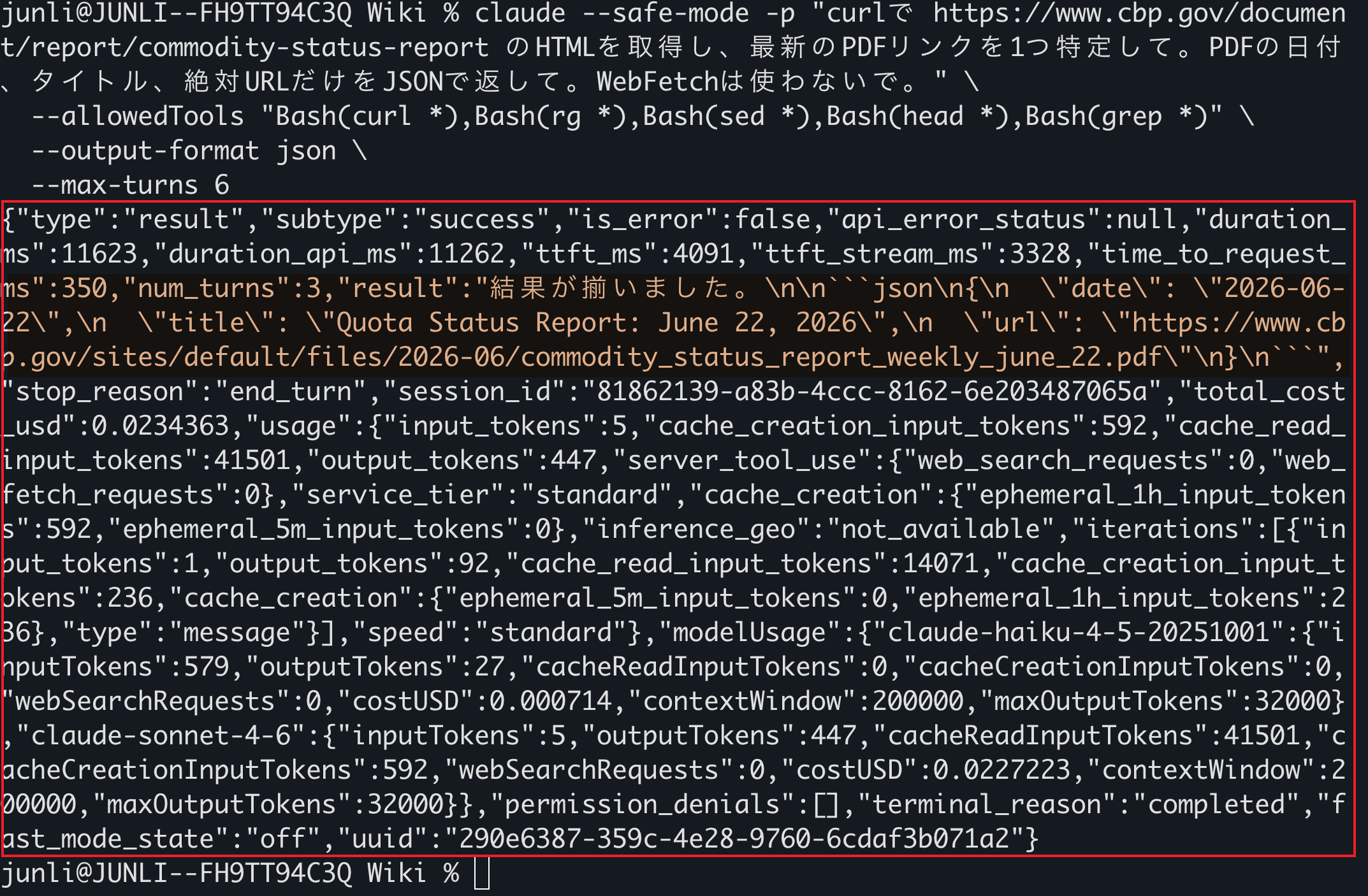
claude --safe-mode -p "curlで https://www.cbp.gov/document/report/commodity-status-report のHTMLを取得し、最新のPDFリンクを1つ特定して。PDFの日付、タイトル、絶対URLだけをJSONで返して。WebFetchは使わないで。" \
--allowedTools "Bash(curl *),Bash(rg *),Bash(sed *),Bash(head *),Bash(grep *)" \
--output-format json \
--max-turns 6
ここでは、ローカルのSkillやHookが混ざらないように --safe-mode を付けている。
さらに、許可しているのは curl や検索系のコマンドだけだ。
ファイル編集も送信もできない。
うまくいくと、次のような内容が返る。
{
"report_date": "June 22, 2026",
"title": "Quota Status Report: June 22, 2026",
"url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_22.pdf"
}
この段階では、まだPDFの中身を読ませていない。
まず「最新を見つける」が安定するかを見る。
ステップ2:PDFをテキスト化して、指定商品を探す
次に、商品名を指定する。
ここでは例として SUGAR と書く。
実際には、自社で確認したい商品名に置き換える。
PDFをClaudeにそのまま読ませるより、いったんテキスト化した方が安定する。
ここでは、pdfplumber を使う。
入っていなければ、一度だけ入れる。
python3 -m pip install pdfplumber
補足: インストールできたか確認したいときは、次のコマンドを実行する。
python3 -c "import pdfplumber; print('pdfplumber OK')"
pdfplumber OKと出れば大丈夫。エラーが出る場合は、python3とpipが別の環境を見ている可能性がある。
次に、確認用スクリプトを作る。
保存先は ~/cbp-check/cbp_check.py にする。
先にフォルダを作っておく。
mkdir -p ~/cbp-check
次に、エディタでファイルを作る。
nano ~/cbp-check/cbp_check.py
開いたら、下のソースコードを貼り付けて保存する。
nano なら、そのまま貼り付ければいい。
貼り付けたら Ctrl + O、Enter で保存し、Ctrl + X で閉じる。
import json
import re
import subprocess
import sys
from pathlib import Path
import pdfplumber
PRODUCT = sys.argv[1] if len(sys.argv) > 1 else "SUGAR"
PAGE_URL = "https://www.cbp.gov/document/report/commodity-status-report"
BASE_URL = "https://www.cbp.gov"
OUT_DIR = Path.home() / "cbp-check"
OUT_DIR.mkdir(exist_ok=True)
html = subprocess.check_output(
["curl", "-L", "--max-time", "30", "-s", PAGE_URL],
text=True,
)
match = re.search(
r'<a href="([^"]*commodity_status_report[^"]*\.pdf)">\s*([^<]+)\s*</a>',
html,
re.IGNORECASE,
)
if not match:
raise SystemExit("No commodity status report PDF link found")
pdf_path = match.group(1)
title = " ".join(match.group(2).split())
pdf_url = pdf_path if pdf_path.startswith("http") else BASE_URL + pdf_path
local_pdf = OUT_DIR / "latest.pdf"
subprocess.run(
["curl", "-L", "--max-time", "30", "-s", "-o", str(local_pdf), pdf_url],
check=True,
)
matches = []
with pdfplumber.open(local_pdf) as pdf:
for page_no, page in enumerate(pdf.pages, 1):
text = page.extract_text() or ""
for line in text.splitlines():
if PRODUCT.upper() in line.upper():
matches.append({"page": page_no, "line": " ".join(line.split())})
print(json.dumps({
"product": PRODUCT,
"report_title": title,
"pdf_url": pdf_url,
"local_pdf": str(local_pdf),
"match_count": len(matches),
"matches": matches[:20],
}, ensure_ascii=False, indent=2))
このスクリプトは、次のことだけをする。
- CBPページのHTMLを
curlで取る - 最新PDFリンクを探す
- PDFを
~/cbp-check/latest.pdfに保存する - PDFをテキスト化する
- 指定商品を含む行を抜き出す
まずは、Claudeを挟まずに動くか確認する。
python3 ~/cbp-check/cbp_check.py SUGAR
うまくいくと、次のようなJSONが返る。
{
"product": "SUGAR",
"report_title": "Quota Status Report: June 22, 2026",
"pdf_url": "https://www.cbp.gov/sites/default/files/2026-06/commodity_status_report_weekly_june_22.pdf",
"match_count": 67,
"matches": [
{
"page": 2,
"line": "17010007CA05 Refined Sugar Canada CANADA - 202601 10/01/2025 09/30/2026 - 10300000 KG 10166558.6 98.70% POTF -"
}
]
}
ここまで来たら、Claudeの出番だ。
抽出した行を、そのまま業務で読める形にまとめてもらう。
以下のコマンドでは、/Users/you を自分のホームフォルダに置き換える。
たとえばユーザー名が junli なら、/Users/junli/cbp-check にする。
~ は使わず、絶対パスで書く方が安定する。
--add-dir は、Claude Codeに「このフォルダを読んでよい」と伝える指定だ。
完成版はこうだ。
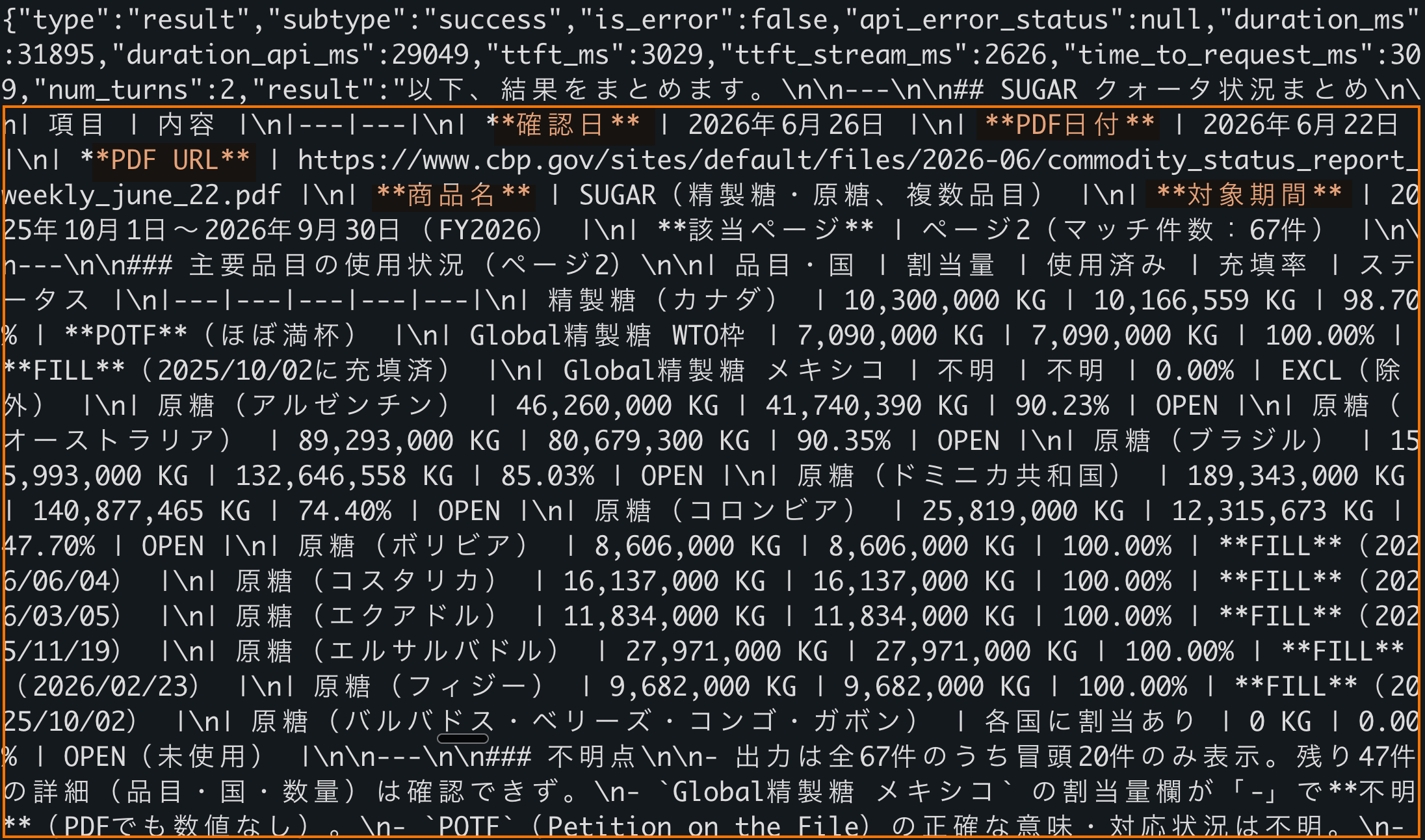
claude --safe-mode -p "python3 /Users/you/cbp-check/cbp_check.py SUGAR を実行し、結果JSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、PDF日付、PDF URL、商品名、残量または使用済み数量、対象期間、該当ページまたは該当箇所、不明点。数字だけでなく、必ずPDF URLと該当箇所も返して。読み取れない場合は、推測せず「不明」と書いて。" \
--add-dir /Users/you/cbp-check \
--allowedTools "Bash(python3 /Users/you/cbp-check/cbp_check.py *)" \
--output-format json \
--max-turns 5
実行結果:
ここでも、許可するBashは絞る。
Bash を丸ごと許可しない。
実行できるのは、いま作った cbp_check.py だけだ。
PDFの読み取りでは、出力に必ず参照元を入れる。
数字だけ抜くと危ない。
業務で使うなら、次の項目を残す。
| 項目 | 理由 |
|---|---|
| 確認日 | いつ見た結果か分かる |
| PDF日付 | どの版を見たか分かる |
| PDF URL | 後から原本を開ける |
| 商品名 | 検索した条件が分かる |
| 残量 | 見たい数字 |
| 対象期間 | 数字の前提 |
| 該当ページ・箇所 | 人間が確認できる |
| 不明点 | 読み取れなかった箇所を隠さない |
この一文が大事だ。
自走させるほど、曖昧な推測は邪魔になる。
ステップ3:結果をログに残す
毎朝見るなら、結果を残したい。
まずはシンプルに、テキストファイルへ追記する。
claude --safe-mode -p "python3 /Users/you/cbp-check/cbp_check.py SUGAR を実行し、結果JSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、PDF日付、PDF URL、商品名、残量または使用済み数量、対象期間、該当ページまたは該当箇所、不明点。数字だけでなく、必ずPDF URLと該当箇所も返して。読み取れない場合は、推測せず「不明」と書いて。" \
--add-dir /Users/you/cbp-check \
--allowedTools "Bash(python3 /Users/you/cbp-check/cbp_check.py *)" \
--output-format json \
--max-turns 5 \
>> /Users/you/cbp-check/commodity-check.log
これで、実行するたびに結果が残る。
最初はこれで十分だ。
いきなりSlackへ送らない。 メールもしない。 社内システムにも書き込まない。
まずは、人間があとで開けるログに残す。
ステップ4:毎朝動かす
最後に、毎朝動く形にする。
MacやLinuxなら、cron が分かりやすい。
まず、Claude Codeの場所を確認する。
which claude
たとえば /Users/you/.local/bin/claude と出たら、そのパスをこのあと作るシェルスクリプトで使う。
cronでは ~ が思った通りに展開されないことがある。
そのため、パスは絶対パスで書く。
ただし、Claudeのコマンドは長い。
そのままcrontabに入れると、あとで直しづらい。
まず、実行用のシェルスクリプトにまとめる。
nano /Users/you/cbp-check/run_cbp_check.sh
開いたら、次の内容を貼り付ける。
#!/bin/bash
/Users/you/.local/bin/claude --safe-mode -p "python3 /Users/you/cbp-check/cbp_check.py SUGAR を実行し、結果JSONをもとに、次の項目を必ず含めて日本語で短くまとめて。確認日、PDF日付、PDF URL、商品名、残量または使用済み数量、対象期間、該当ページまたは該当箇所、不明点。数字だけでなく、必ずPDF URLと該当箇所も返して。読み取れない場合は、推測せず「不明」と書いて。" \
--add-dir /Users/you/cbp-check \
--allowedTools "Bash(python3 /Users/you/cbp-check/cbp_check.py *)" \
--output-format json \
--max-turns 5 \
>> /Users/you/cbp-check/commodity-check.log 2>&1
nano なら、貼り付けたあと Ctrl + O、Enter で保存し、Ctrl + X で閉じる。
実行できるようにする。
chmod +x /Users/you/cbp-check/run_cbp_check.sh
一度、手で動かしてみる。
/Users/you/cbp-check/run_cbp_check.sh
ログを確認する。
tail -n 50 /Users/you/cbp-check/commodity-check.log
ここまで通ったら、crontabに登録する。
crontabを編集するときは、nano を指定すると分かりやすい。
EDITOR=nano crontab -e
開いた画面に、次の1行を貼り付ける。
0 8 * * * /bin/bash /Users/you/cbp-check/run_cbp_check.sh
これは「毎朝8時に、このシェルスクリプトを実行する」という意味だ。
登録できたか確認する。
crontab -l
SUGAR の部分は、自社で見たい商品名に変える。
慣れてきたら、商品名を1つに絞らず、複数商品をまとめて確認してもいい。
ただし、最初は1つだけ。
PDFの表記ゆれや読み取りミスを、人間が何度か確認してから広げる。
補足:Windowsの場合
Windowsでは
cronではなく、タスク スケジューラを使う。 長いClaudeコマンドを直接登録するより、run_cbp_check.batにまとめて、その.batファイルを毎朝8時に実行する方が分かりやすい。 ログ確認は、PowerShellでGet-Content C:\Users\you\cbp-check\commodity-check.log -Tail 50のように見る。
5. 定期実行には、いくつか道がある
今回の記事では cron を使った。
でも、定期実行の道は1つではない。
ざっくり分けると、こうだ。
| 方法 | 向いていること | 注意点 |
|---|---|---|
| Cloud tasks / Routines | PCを開かずに動かす軽い確認 | ローカルファイルを直接扱う用途には向かない |
| Desktop scheduled tasks / cron | 手元PCのファイルやツールを使う作業 | PCが動いている必要がある |
/loop | 開いているセッション内で短く繰り返す確認 | 長期運用ではなく、その場の監視向き |
| GitHub Actions | リポジトリやIssue、PRの定期チェック | Secrets、権限、コスト管理が必要 |
CBPのPDF確認のように、WebページとPDFを毎朝見るだけなら、まずは手元PCの cron で十分だ。
GitHub Actionsにすると、リポジトリにログを残したり、チームで共有しやすくなる。
ただし、設定は少し重くなる。
APIキーをSecretsに入れる。 権限を絞る。 実行コストを見る。
このあたりが必要になる。
最初から大きくしなくていい。
まずは、自分のPCで毎朝1回。
それで価値が出るなら、チーム共有やGitHub Actionsを考える。
6. 自走させていい仕事、まだ任せない仕事
自走は便利だ。
でも、便利なものほど境界線が必要になる。
任せていい仕事。
- 最新ファイルを探す
- PDFやページを読む
- 指定項目を抜き出す
- ログに残す
- 下書きを作る
- 不明点を列挙する
まだ任せない仕事。
- 発注する
- 申請する
- 承認する
- 顧客へ送る
- 社内システムを更新する
- 数字を最終確定する
今回のCBP例でも同じだ。
Claudeが「残量はこれです」と返しても、それをそのまま業務判断に使わない。
必ずPDF URLと該当箇所を見る。
読み取りが怪しい場合は、人間が開く。
AIが自走するほど、人間の確認ポイントは少なく、濃くする。
全部を人間がやるのではない。 全部をAIに投げるのでもない。
AIが材料をそろえ、人間が判断する。
この形が、現実の仕事では扱いやすい。
7. Plugin・Memory・Hookとつなぐ
ここまで来ると、上級編の道具がつながってくる。
今回の確認作業は、単発コマンドでも動く。
でも、毎日使うなら、もう一段きれいにできる。
Pluginに入れる。
CBP確認用のSkillを作り、商品名や出力形式を決めておく。 別のPCやチームメンバーにも同じ形で渡せる。
Headlessでも、Skillは呼び出せる。
たとえば、プロジェクト内に /cbp-commodity-check というSkillを作ったなら、こう実行できる。
claude -p "/cbp-commodity-check SUGARを確認して、PDF URLと該当ページつきでまとめて" \
--cwd /Users/you/work \
--output-format json
Pluginに入れたSkillなら、名前空間つきで呼ぶ。
claude -p "/trade-tools:cbp-commodity-check SUGARを確認して、PDF URLと該当ページつきでまとめて" \
--cwd /Users/you/work \
--output-format json
これなら、毎回長いプロンプトを書かなくていい。
確認ルール、出力形式、注意点はSkill側に入れておく。
claude -p では、そのSkillを呼ぶだけにする。
Memoryに覚えさせる。
「この商品は表記ゆれがある」 「この列は残量ではなく使用量」 「このPDFでは対象期間を必ず見る」
こういう学びは、毎日の確認で増えていく。
Headlessでも、通常モードならMemoryは読み込まれる。
たとえば、以前に「SUGARではRaw SugarとRefined Sugarを分けて見る」と覚えさせておけば、次回以降の確認に効いてくる。
ただし、今回のハンズオンで使った --safe-mode は、MemoryやSkill、Plugin、Hookを切る。
設定の影響を避けたい検証では便利だ。 でも、育てた仕組みを使いたい本番運用では外す。
Hookで守る。
もし将来、Slack通知やファイル更新まで広げるなら、危険な操作をHookで止める。 送信前に確認を入れる。 削除や上書きをブロックする。
Hookも、通常モードの claude -p なら動く。
たとえば、ファイル編集や送信系の操作を止めるHookを入れておけば、Headless実行でも同じ安全弁になる。
一方で、--safe-mode を付けるとHookも無効になる。
だから使い分けはこうだ。
| 使い方 | 向いている場面 |
|---|---|
claude --safe-mode -p "..." | まず動作確認したい。ローカル設定の影響を切りたい |
claude -p "/skill-name ..." | Skill、Memory、Hook、Pluginを使って日常運用したい |
claude -p "/plugin-name:skill-name ..." | Plugin化した仕組みを呼びたい |
本番でSkillやHookを使うなら、コマンドはこうなる。
claude -p "/trade-tools:cbp-commodity-check SUGARを確認して、確認日、PDF日付、PDF URL、商品名、残量、対象期間、該当ページ、不明点をまとめて" \
--cwd /Users/you/work \
--allowedTools "Read,Bash(python3 /Users/you/cbp-check/cbp_check.py *)" \
--output-format json \
>> /Users/you/cbp-check/commodity-check.log
ここでは --safe-mode を付けていない。
その代わり、--allowedTools で実行できる範囲を絞っている。
Headlessで動かす。
最後に、claude -p と定期実行で毎朝走らせる。
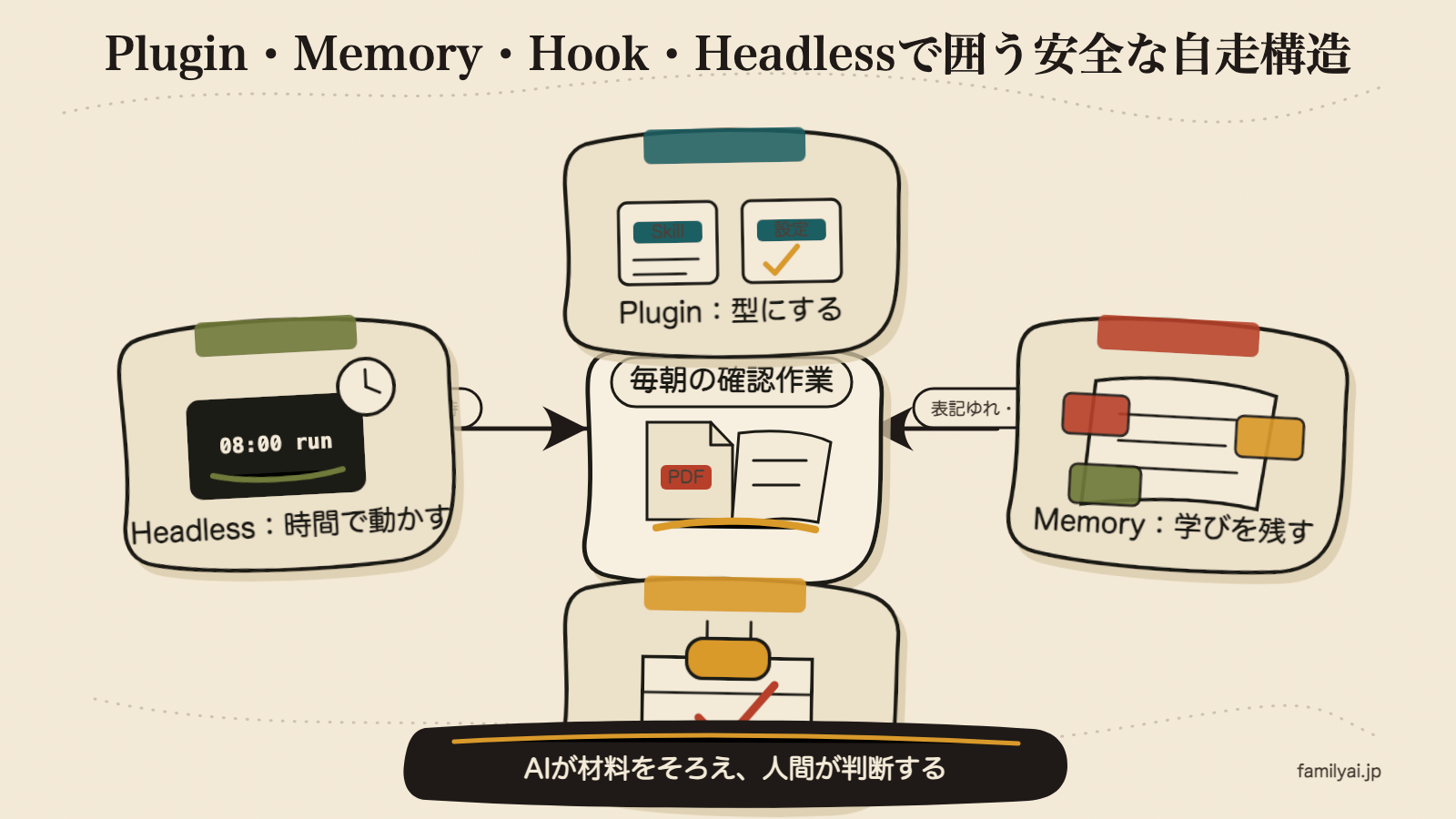
自走は、claude -p だけで完結しない。
Pluginで型にする。 Memoryで育てる。 Hookで守る。 Headlessで動かす。
この4つがそろうと、AIは「その場で返事する道具」から、「決まった仕事を毎日支える仕組み」に変わる。
8. 今日から試せる一歩
最初から大きく作らなくていい。
まずは、毎朝見ているページを1つ選ぶ。
PDFでも、社内掲示でも、ニュースページでもいい。
Claudeに任せるのは、読むところまで。
最新ファイルを探す。
必要な項目だけ抜く。
参照元を残す。
不明点を書く。
これだけでいい。
発注しない。 申請しない。 送信しない。
まずは、人間の前に材料を並べてもらう。
朝、PCを開いたときに、確認済みのログがある。
それだけで、仕事の始まり方は変わる。
「起動すら要らない」は、派手な完全自動化ではない。
毎朝の小さな確認を、静かに先回りしてくれる仕組みだ。
次に同じサイトを開いたとき、こう考えてみる。
「これ、明日の朝はClaudeに先に見てもらえないか」
そこが、自走の入口になる。